고정 헤더 영역
상세 컨텐츠
본문
728x90
반응형
최근 '챗GPT'와 같은 대규모 언어모델(LLM)이 전 세계적인 관심을 받으며, 인공지능(AI) 기술에 대한 기업들의 관심이 급증하고 있습니다. 이러한 상황에서, 특히 주목받고 있는 기술이 있으니, 바로 '소규모 언어모델(sLLM)'입니다. sLLM은 매개변수(parameter)의 수를 대폭 줄인 맞춤형 LLM으로, 비용 절감과 함께 미세조정(fine-tuning)을 통해 특정 분야에서의 정확도를 높이는 것을 목표로 합니다.
※ sLLM (smaller Large Language Model): 큰 언어 모델(Large Language Model) 중에서도 상대적으로 작은 크기를 가진 모델
1. sLLM의 등장 배경
1.1. 대규모 모델의 한계와 비용 문제
GPT-3.0과 GPT-3.5(챗GPT)는 1750억 개, 구글의 PaLM은 5400억 개의 매개변수를 가지고 있습니다. 이러한 대규모 모델은 학습에 수개월이 걸리고, 비용도 수십만에서 수백만 달러에 달하는 큰 비용이 발생합니다. 반면, sLLM은 매개변수를 60억~70억 개로 줄여 학습 시간과 비용을 대폭 절감할 수 있는 장점을 제공합니다.
1.2. 맞춤형 AI의 필요성 증가
기업들은 '세상의 모든 정보'를 필요로 하지 않습니다. 오히려 기업이 보유한 비공개 데이터나 특정 분야에 초점을 맞춘 데이터 학습이 더 중요합니다. sLLM은 이러한 맞춤형 AI 솔루션을 가능하게 하는 기술로 부상하고 있습니다.
2. sLLM의 장점과 기업들의 적용 사례
2.1. 비용과 시간 절감
데이터브릭스의 '돌리'는 학습에 3시간이 소요되며 비용은 30달러에 불과했습니다. 이는 기존 LLM에 비해 혁신적인 비용 절감을 의미합니다.
2.2. 고품질 데이터 학습을 통한 성능
sLLM은 특정 분야에서 고품질의 데이터 학습을 통해 기존 LLM과 맞먹는 성능을 보여줍니다. 이를 통해 기업들은 자신들의 요구사항에 맞춤화된 AI 모델을 구축할 수 있습니다.
2.3. 기업 사례

메타의 라마: 매개변수를 줄이고, 훈련에 사용하는 텍스트 데이터 단위인 토큰의 양을 늘려 품질을 높인 모델을 제공합니다. 특히 7B 버전은 매개변수가 70억 개에 불과해 소규모 장치에서도 운용이 가능합니다.

스탠포드대 연구진의 알파카: 라마 7B를 기반으로 한 sLLM 모델로, 특정 분야의 깊이 있는 데이터 학습이 가능합니다.
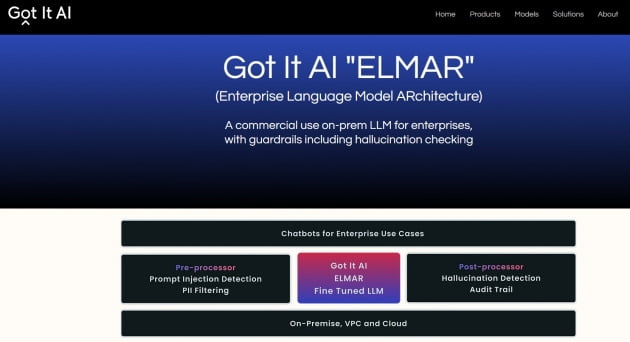
갓잇AI의 엘마: 온프레미스 형태로 제공되며, 기업 데이터가 외부에 공개되지 않는 환경에서 머신러닝을 가능하게 합니다.
3. sLLM의 미래와 기업 전용 LLM으로의 변화
sLLM은 각 기업이 자신만의 맞춤형 AI 모델을 구축하는 데 있어 큰 역할을 할 것으로 예상됩니다. 시스코의 지투 파텔 수석부사장은 모든 회사가 다른 기업에서 복제할 수 없는 '사용자 지정 데이터셋'을 가지게 되고, 이를 기반으로 특정한 AI 모델을 가지게 될 것이라고 말했습니다. 이는 기업마다 독특한 가치와 서비스를 제공할 수 있는 기회를 의미합니다.
테크크런치의 예측처럼, 작고 유연한 모델이 기업마다 맞춤형으로 사용할 수 있는 AI 모델을 구축하는 데 더 효과적일 것입니다. 이는 AI 기술의 발전뿐만 아니라, 기업들이 AI를 어떻게 활용해 경쟁력을 강화할 수 있는지에 대한 새로운 패러다임을 제시합니다.
4. 결론
소규모 언어모델(sLLM)의 등장은 AI 기술의 새로운 지평을 열고 있습니다. 비용과 시간을 대폭 절감하면서도 특정 분야에서 높은 정확도를 제공하는 sLLM은 기업들이 AI를 도입하고 활용하는 방식에 혁신을 가져올 것입니다. 앞으로 sLLM은 기업 전용 LLM으로 발전하며, 각 기업의 고유한 요구사항과 데이터를 반영한 맞춤형 AI 모델 구축의 중심축이 될 것으로 기대됩니다. 이러한 변화는 기업들이 AI 기술을 활용해 더욱 창의적이고 혁신적인 방법으로 발전할 수 있는 발판을 마련해줄 것입니다.
728x90
반응형
'IT' 카테고리의 다른 글
| 오픈AI와 구글의 AI 기술력 경쟁, 미래를 향한 거대한 도전 (129) | 2024.02.17 |
|---|---|
| AI: 인공지능의 현실과 미래 (25) | 2024.02.17 |
| 2024년 주목해야 할 AI 트렌드 3가지 (57) | 2024.02.14 |
| 5. 사이버 보안: 디지털 전선을 지키는 방법 (8) | 2024.02.11 |
| 4. 클라우드 컴퓨팅과 서비스: 디지털 혁신의 핵심 동력 (6) | 2024.02.11 |




